Imagine that you are a freelance translator, and your customer asked you to translate a file in PDF format. As usual, PDF files are recognized, and it is not a problem to count words. Just copy the text to MS Word and perform word counting using a built-in word count tool. So, you implicitly agree on this job. But when you get this PDF file and open it, you understand that it is unrecognized. So how to do a word count in unrecognized PDF?
There is possible to combine in PDF both recognized text and unrecognized images. Let’s also imagine that, unfortunately, you disagreed with your customer that for scan jobs, you are paid on a per hour basis, and therefore your customer demands a job to be done on a per word basis. So, you need to count words in this PDF file in any way. How can you perform this? There are two methods to count words in PDF files: free of charge and paid…
Free method to perform word count in unrecognized PDF
Let’s begin from the free of charge method. So, to count the unrecognized PDF files, you need to recognize them at first. It is cool if you have already bought some good paid OCR programs like Abbyy FineReader or Adobe Acrobat Professional, a built-in OCR tool. But we are reviewing free of charge ways to count unrecognized PDF files, and therefore we need to get a free OCR tool to recognize your PDF file.
After searching for free OCR tools, I chose FreeOCR because this program can recognize PDF files. You can download Free OCR at http://www.paperfile.net/download.html
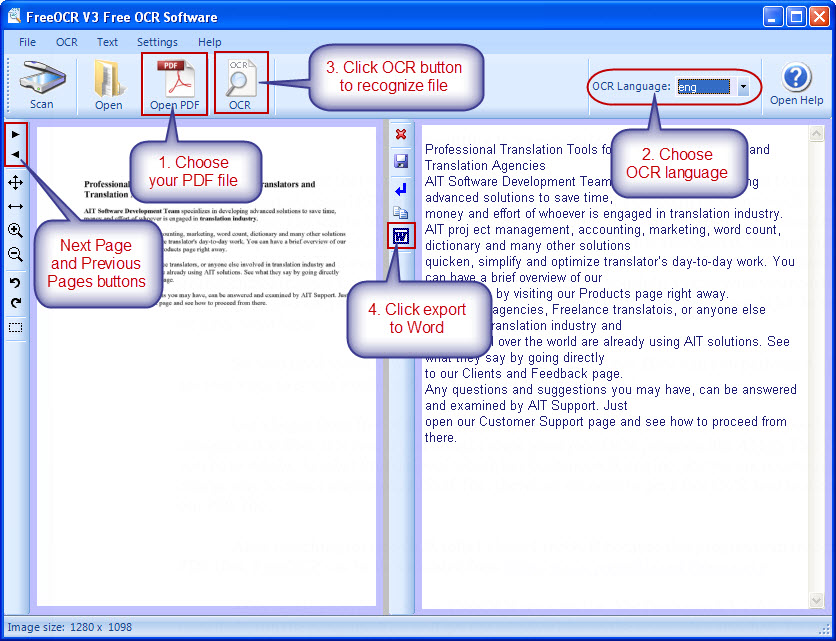
After installation (by the way, FreeOCR requires the .Net Framework V2.0 from Microsoft installed) to run the program. You will get a window like on the screenshot attached. To recognize a PDF file, click the Open PDF button, choose your PDF file, choose OCR language, and then click the OCR button. After recognition, export the text, which you have got, to Word.
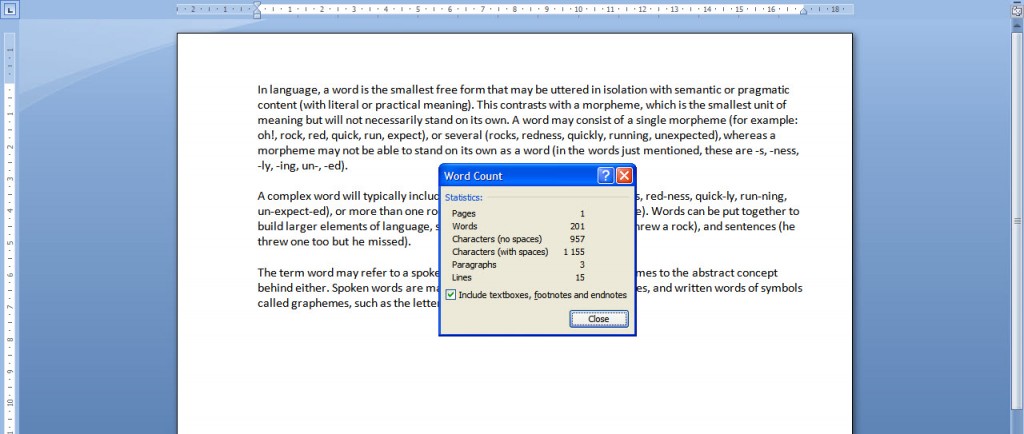
Get some statistics using the MS Word built-in tool (MS Word 2007, click Review > Word Count).
But I would like to draw your attention to that downloaded FreeOCR has only the English OCR language installed. More OCR languages you can find out on http://www.paperfile.net/lang.html
So, let’s see the summary of this free way:
Pros:
Free of charge
Contras:
Time-consuming process.
Only English OCR language installed. Thus it is necessary to download the other languages from the website.
A small number of OCR languages is available.
The program can recognize only one page per one time. Therefore you need to switch pages if you have more than one page in your PDF file.
Sometimes you will see mistakes in a recognized file.
The recognized text doesn’t erase when you open and recognize a new document.
Since the software is free of charge, you cannot be 100% sure that it is entirely safe for your information.
Not wholly accurate counting by MS Word.
Another free way to do word count in unrecognized PDFs
You can also submit your file to a free online OCR at http://www.free-ocr.com/ (OCR available only for English, German, French, Italian, Dutch, or Spanish). This method has almost the same pros and contras as the previous method, plus there is a more significant risk for the safety of your information, and you should wait while your file will be downloaded on the website.
Notice that you need to have good quality and resolution of images in your unrecognized PDF file to ensure the most accurate word count for all methods considered in this article.
Better word count alternative
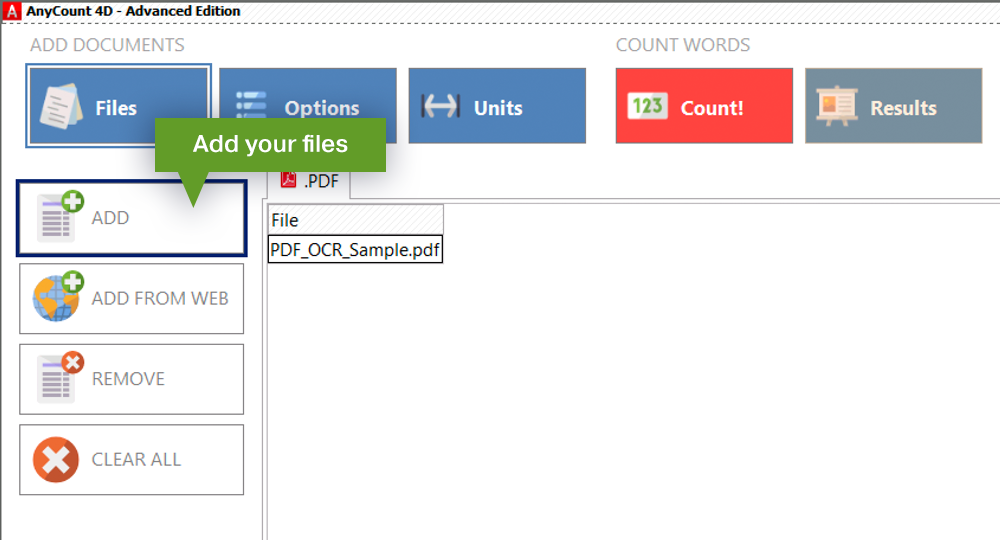
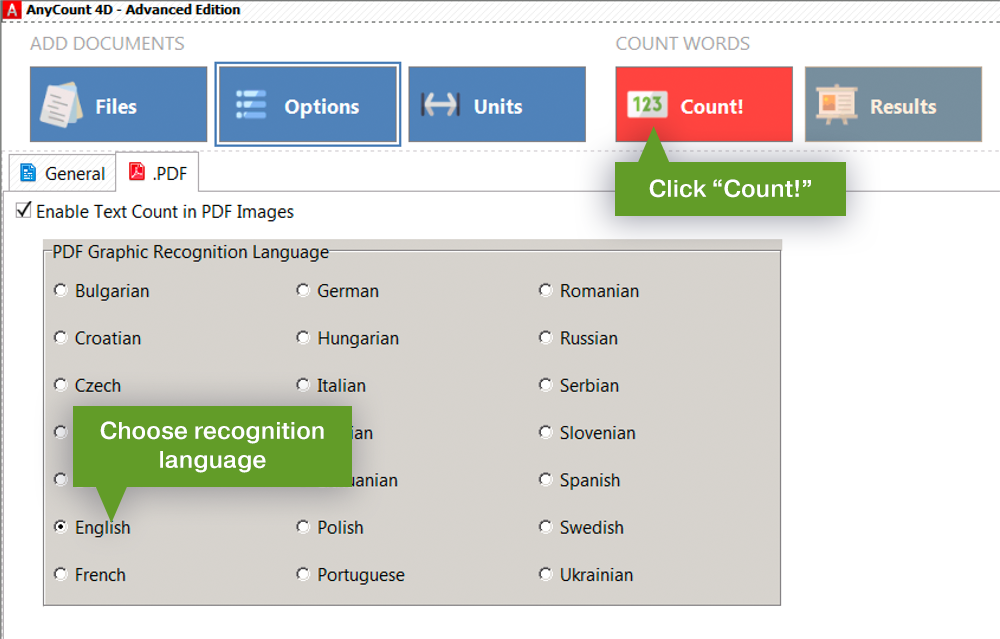
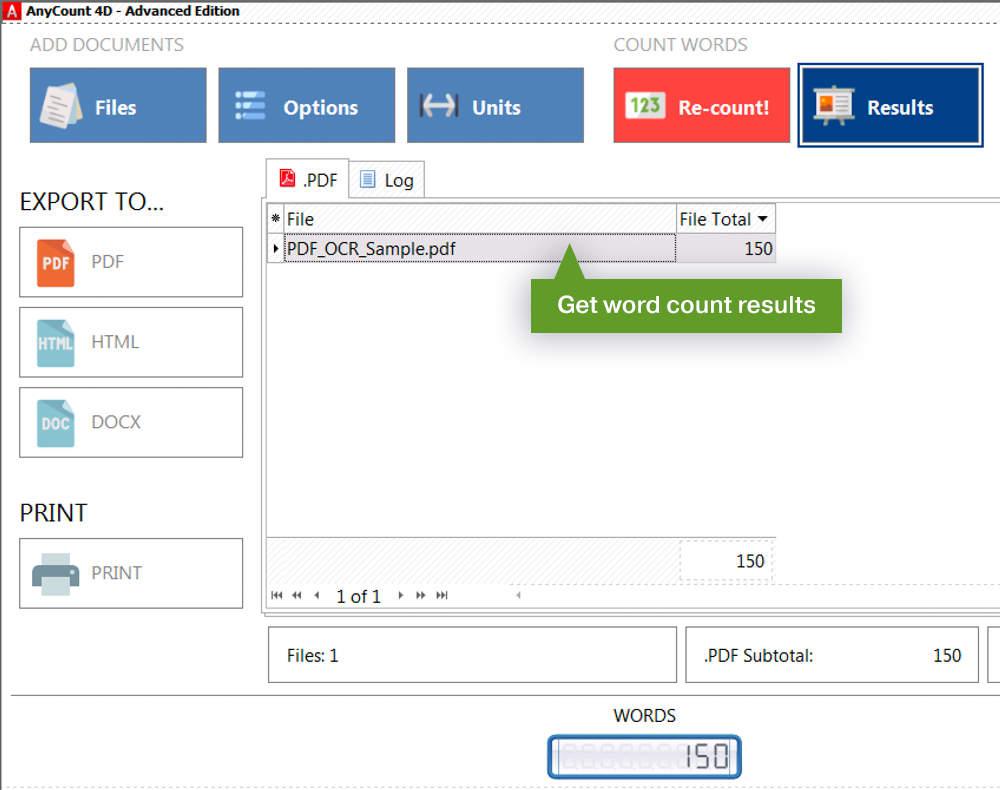
Now I propose to consider the paid alternative. There is software which has been developed especially for counting. As an example, I will consider AnyCount software. This program can count words, characters, and lines in 70 formats. Also, it can count words in unrecognized PDF files. To perform word count in such a PDF file, you need to choose a PDF Graphic Recognition language and click the Count button. The program will recognize your PDF file and count it automatically.
The summary of the paid way of word count in unrecognized PDF files is the following:
Pros:
Time-saving process. You do not need to spend your time on the recognition of the PDF file.
Support for more than 20 graphic recognition languages.
Accuracy counting.
Support counting for more than 35 formats. Therefore you will be able to use the program to count most of your files.
Word count tool is developed by the reliable, well-known software company Advanced International Translations Ltd. It develops software for the translation industry (such as Projetex, Translation Office 3000, AceProof, ExactSpent, etc.) since 2001. Thus you can be sure that third parties will not use your information.
Contras:
Paid
So, as you may see, the free variant of word count in unrecognized PDF is reasonable to use as a temporary and quick one-time solution. If you need a swift and extensive word count (or any other statistics, like character and line count), it is better to use professional word count software.
Try Anycount now! Download the word count tool absolutely free.



5 Comments
Titan
There may be noticeably a bundle to learn about this. I assume you made certain good points in features also.
Rocket Spanish
Hi. Thank you for this great post. I searched this all day and finally I found it through your site. Also I’m a spanish teacher. Thanks again 🙂
Kat
In my Anycount 7 version, the Enable PDF Graphic Recognition is grayed out. How do I activate it?
Mikhail Sergievskiy (AIT)
Dear Kat, most likely you use AnyCount 7, Professional edition. Professional edition supports units count in PDF text layers only. To process images in PDF documents (including scanned PDF files) you would need to use AnyCount, Enterprise edition. Please see more here: https://aithelp.com/index.php?/Knowledgebase/Article/View/595/0/what-languages-are-supported-by-anycount-for-pdf-file-format
You can upgrade your existing license to the latest version and enhance the edition to Enterprise by ordering upgrade.
Maria
What a great post. Thank you so much.
Regards,
Maria