In an ideal world, clients always provide you with perfect translation files. You have no difficulty in opening them and processing a word or character count. But the reality is that customers can send you photos or scanned documents instead of text files, and you also need to work with that. To get scanned texts in PDF format is very common. So how to do word count in OCR files?
To extract the text and get a word-count, you need Optical character recognition or optical character reader (OCR). OCR is the automatic conversion of pictures with typed text, handwritten, or printed text into the machine-encoded text from a scanned file, or a photo of your docs.
There are a few ways how you can count the number of words in your scanned PDF, or word count in OCR files.
You can convert your PDF to Word documents online. The ability to convert scanned documents induces additional costs often, but you can find free converters with a limit on the number of uploaded files. You can easily Google such services. How to convert scanned PDF to DOC/DOCX files online:
Access PDF to Word converter through Google search.
Upload your PDF document via drag-and-drop.
Click the Convert button
The OCR tool will activate as it detects the PDF as a scan.
Wait till the conversion is done.
Download your editable DOC/DOCX file.
Open your DOC/DOCX in any version of Microsoft Word.
Find more tips on counting words in Microsoft Word in our recent posts:
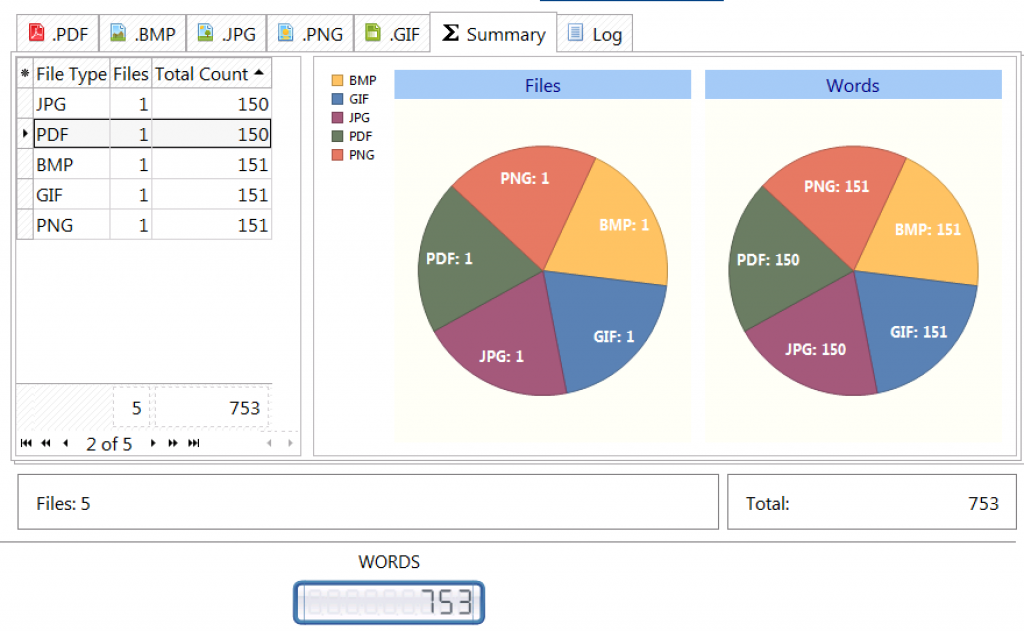
Use smart word-count tools for any of your PDF files and images. AnyCount can simply count words, characters, and lines in text PDF files and scanned texts saved in PDF, PNG, JPG, BMP, and GIF. Try AnyCount freehere.